Libreng OCR software upang i-extract ang teksto mula sa mga file ng larawan at mga item na PDF. Ang graphical user interface (GUI) para sa Tesseract OCR engine.
Application ay simple upang i-install at, mas mahalaga, malayang gamitin, open-source at 100% ng adware at spyware libre.
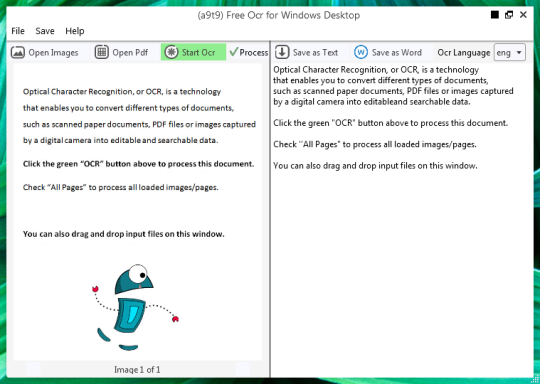
Maaari mong buksan ang isang imahe o PDF file. Ang nilalaman ng source file ay ipapakita sa kaliwang window. Kung ang iyong dokumento bilang higit sa isang pahina, o kung binuksan mo ang mga dokumento multi-page, gamitin ang mga arrow sa ibaba upang magpalipat-lipat sa pagitan ng mga ito,
Mong simulan ang OCR sa pamamagitan ng pag-click sa berdeng pindutan OCR, at makikita mo ang resulta sa pangalawang kanan window. Maaaring i-save ang output ng teksto bilang isang text file o Word dokumento.
Sa kasamaang palad ang kalidad ng conversion ay hindi kaya mahusay. Sa likod ng mga eksena ginagamit nito ang Tesseract open-source na OCR engine. Ang kalidad ay nag-iiba mula sa wika sa wika -. Kaya sige at pagsubok kung ito ay sapat para sa iyong mga pangangailangan
Para sa mga developer software at geeks: Ang libreng OCR para tool Windows Desktop ay mahalagang isang graphical user interface na front-end (GUI) para sa Tesseract OCR engine. Ang buong pinagmulan-code ay magagamit (GPL lisensya).
Ang OCR engine ng software na sumusuporta sa mga sumusunod na wika OCR: Ingles, Pranses, Italyano, Aleman, Espanyol, Brazilian Portuguese at Olandes. Simula sa bersyon 3 maaari itong makilala Arabic, Bulgarian, Catalan, Chinese (Pinasimple at Tradisyunal), Croatian, Czech, Danish, Olandes, Ingles, Aleman (karaniwang at Fraktur script), Griyego, Finnish, Pranses, Hebrew, Hindi, Hungarian, Indonesian, Italyano, Japanese, Korean, Latvian, Lithuanian, Norwegian, Polish, Portuges, Romanian, Russian, Serbian, Eslobako (karaniwang at Fraktur script), Eslobenyan, Espanyol, Suweko, Tagalog, Tamil, Thai, Turkish, Ukrainian at Vietnamese.
Mga Komento hindi natagpuan