Kilalanin text mula sa mga imahe gamit ang Tesseract OCR Engine batay sa mga teknolohiya ng ulap.
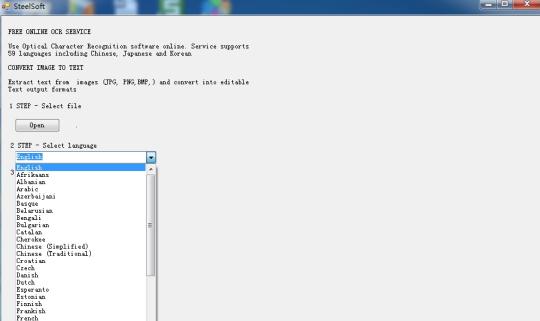
Gamitin Optical software Character Recognition online. Service sinusuportahan 59 wika kabilang ang Chinese, Japanese at Korean. I-extract ang teksto mula sa imahe (JPG, PNG, BMP, TIF) at i-convert sa e-edit na format Text output.
Ito ay batay sa teknolohiya ng ulap, at ang napaka-tanyag na OCR engine (Tesseract OCR Engine), kaya mayroon lamang daan-daang mga KB sa laki, ngunit ito ay maaaring kunin ng text sa 59 mga wika, mula sa mga imahe.
Ito ay sumusuporta sa higit pang mga wika: Bulgarian, Catalan, Czech, Danish, Olandes, Ingles, Finnish, Pranses, Aleman, Griyego, Hungarian, Indonesian, Italian, Latvian, Lithuanian, Norwegian, Polish, Portuguese, Romanian, Russian, Serbian, Slovak, Slovene , Spanish, Swedish, Tagalog, Turkish, Ukrainian, Vietnamese atbp
Ano ang bagong sa paglabas:..
Version 5.0 kasamang mga pagpapabuti UE

Mga Komento hindi natagpuan