
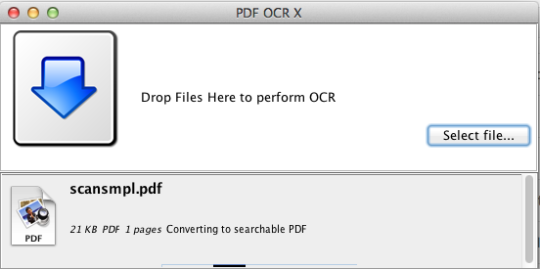
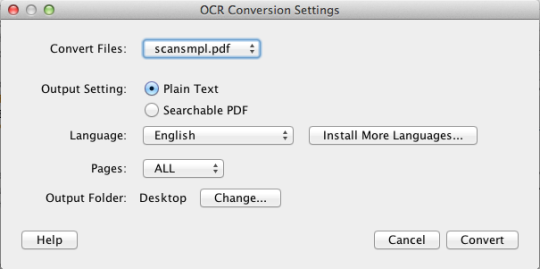
Ang PDF OCR X ay isang simpleng utility na drag-and-drop para sa Mac OS X, na nag-convert ng iyong mga PDF at imahe sa teksto o nahahanap ang mga dokumentong PDF. Gumagamit ito ng advanced na teknolohiya ng OCR (optical character recognition) upang kunin ang teksto ng PDF (o larawan) kahit na ang tekstong iyon ay nasa isang imahe. Ito ay partikular na kapaki-pakinabang para sa pagharap sa mga PDF at mga imahe na nilikha sa pamamagitan ng isang Scan-to-PDF function sa isang scanner o copier ng larawan. Sinusuportahan ang mahigit 60 wika para sa OCR. Ang OCR engine ay batay sa Tesseract. Sinusuportahan ng Community Edition ang mga PDF na pahina ng single page (o ang unang pahina ng mga PDF na multi-pahina). Para sa multi-pahina na suporta ng PDF dapat kang mag-upgrade sa Enterprise Edition.
Ano ang bago sa paglabas na ito:
Bersyon 2.1.1 ay nagdaragdag ng suporta para sa Mojave , at nagpapabuti sa UI sa mga display ng retina.
Ano ang bago sa bersyon 2.0.8:
Fixed isyu sa paghawak ng ilang mga PDF na may pag-ikot. >
Mga Limitasyon :
Ang Community Edition ay limitado sa mga pahinang PDF at imahe na may isang pahina.



Mga Komento hindi natagpuan